Definition of Spark vs MapReduce
Spark vs MapReduce is an open-source distributed system that is used to handle the workloads of big data. The Spark and MapReduce framework improves the performance of query processing in varying data sizes by using good execution of the query and caching into the memory. MapReduce is a distributed computing model of java that was used in the framework of HDFS, it is used to access large data.
Table of contents
Difference Between Spark vs MapReduce
Basically spark processes data in the RAM, while MapReduce persists data in the disk after the action of MapReduce. Spark requires lots of memory while MapReduce does not require a lot of memory, it will store data on the disk. Spark loads the process in the memory and keeps it until further notice for caching purposes.
While running spark on YARN for service of resource demanding, if the data is too large to fit in the memory, then spark suffers major in performance. MapReduce kills the process when its job is done.
What is Spark?
Spark is rapidly growing and is a new open-source technology that works with clusters in the nodes. Apache is a hallmark of spark. Developers work the environment by using an application interface that is based on RDD. This is nothing but the abstraction provided by a spark that segregates the node in clusters of smaller divisions for processing the data.
Apache spark is a fast and general engine that was used for processing the data. Apache spark is faster as compared to MapReduce, it is the most preferred tool for data analytics. We are using apache spark to include distributed SQL.
What is MapReduce?
MapReduce is a programming model of distributed computing which is used in the framework of HDFS. We are using the same for accessing a large amount of data.
In MapReduce, we perform the mapper and reducer jobs in the MapReduce programming. The mapper is responsible to sort the available data, while we are using a reducer in turning and aggregating it into small chunks. Mapreduce is the framework on which we can write the functions to process massive data in giant clusters.
Mapreduce is the processing method for the application model which was dispensed based on java. The MapReduce algorithm incorporates two tasks i.e. map and reduce. The map takes a set of records and converts the same in other sets of data whether a factor is broken down into pairs of keys and values.
Head to Head Comparison Between Spark vs MapReduce (Infographics)
Below are the top 13 differences between Spark vs MapReduce:
Key Differences between Spark vs MapReduce
Let us look at the key differences between Spark and MapReduce:
- Apache spark contains the API of java, Scala, Python, and Spark SQL for the users of SQL. Apache spark provides building blocks of the function which was user-defined. Mapreduce is developed by using java.
- Apache spark provides multiple tasks for data processing, it handles graphs for the ML libraries. We are using the MapReduce framework for batch processing, if we want a real-time solution, then we can use the Impala.
- Spark is popular due to its speed because it processes data on RAM, and spark takes a lot of RAM for operating effectively. Mapreduce does not provide caching of data, so the performance of MapReduce is less as compared with spark.
- Mapreduce is suitable for recovery as compared to the spark because it uses a hard disk instead of RAM. Spark is not comfortable for recovery because it stores data in RAM.
- In apache spark, security is set as OFF by default, it uses the channel of RPC authentication through shared secret. Mapreduce uses higher security as compared to spark because it uses LDAP authentication.
- Spark is an open-source project. We need to spend more money on RAM while using Spark. While MapReduce is also open source, we must spend it on disc storage when using it.
Spark Requirement
At the time of installing spark in our system, we need to check whether the following software is installed in our system are as follows.
- First, we need to install the stack version of HDP cluster 3.0+
- Second, we need to install a version of ambari 2.7+
- Need to deploy the yarn and HDFS in our cluster.
While installing the above software, we also need to check the following software and the requirement for spark as follows.
- The hive needs to be installed in our cluster.
- Need to install the R binaries on our server.
- Need to install livy in the spark cluster.
- Need to install python 2.7+ installed on all nodes.
MapReduce Requirement
The IBM Spectrum symphony supports the framework of MapReduce on Linux. To install the framework of MapReduce, it is recommended to use the Linux operating system. We are using the MapReduce framework on multiple distributed file systems. Below are the minimum hardware requirements at the time of using the MapReduce framework are as follows.
- We require single or more management and compute hosts.
- We require 2.4 GHz CPU power for the management and compute host.
- We require 4 GB RAM for the management host and 1 GB RAM for compute host.
- We require 1 GB disk space for installing management and compute host.
- We require 30 GB of additional space for the management host and 10 GB for compute host.
Basically, the framework of MapReduce is available only with IBM and the spectrum symphony of IBM.
Comparison Table of Spark vs MapReduce
The table below summarizes the comparisons between Spark vs MapReduce:
| Spark | MapReduce |
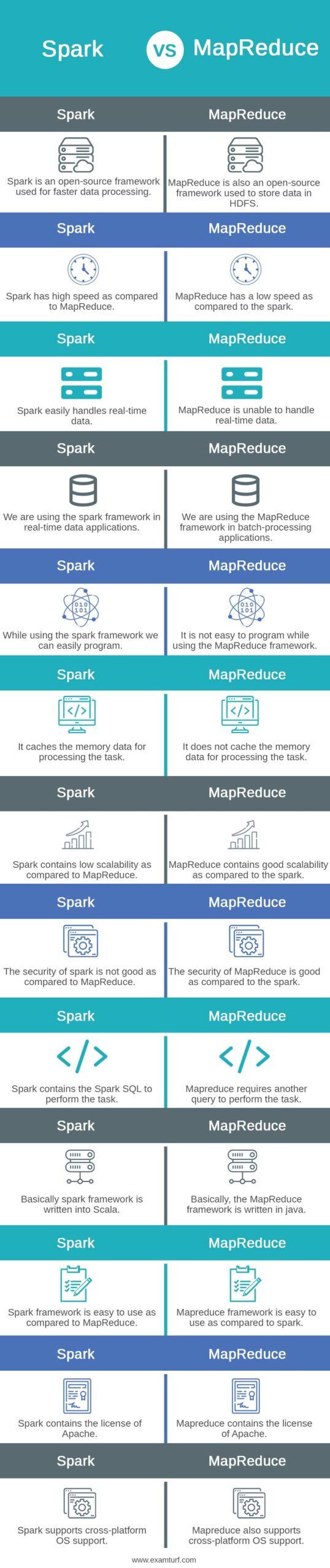
| Spark is an open-source framework used for faster data processing. | Mapreduce is also an open-source framework used to store data in HDFS. |
| Spark has high speed as compared to MapReduce. | Mapreduce has a low speed as compared to the spark. |
| Spark easily handles real-time data. | Mapreduce is unable to handle real-time data. |
| We are using the spark framework in real-time data applications. | We are using the MapReduce framework in batch-processing applications. |
| While using the spark framework, we can easily program. | It is not easy to program while using the MapReduce framework. |
| It caches the memory data for processing the task. | It does not cache the memory data for processing the task. |
| Spark contains low scalability as compared to MapReduce. | Mapreduce contains good scalability as compared to the spark. |
| The security of spark is not good as compared to MapReduce. | The security of MapReduce is good as compared to the spark. |
| Spark contains the Spark SQL to perform the task. | Mapreduce requires another query to perform the task. |
| Basically spark framework is written into Scala. | Basically, the MapReduce framework is written in java. |
| Spark framework is easy to use as compared to MapReduce. | Mapreduce framework is easy to use as compared to spark. |
| Spark contains the license of Apache. | Mapreduce contains the license of Apache. |
| Spark supports cross-platform OS support. | Mapreduce also supports cross-platform OS support. |
Purpose of Spark
Apache spark contains the built-in API of java, Scala, and spark SQL. Apache spark is a widely used open-source big data framework widely used and is considered the successor to MapReduce framework used to process the data. Spark offers an easy and fast way to analyze the data across the clusters. We are using spark in machine learning.
Spark is a unified programming model that allows developers to choose from when building applications. There will be no maintenance required when using Apache Spark. Spark allows multiple map operations into the spark framework’s memory.
Purpose of MapReduce
Mapreduce is nothing but the program model used for distributed computing, and it is based on java. The MapReduce framework is easily scaled, so we can add multiple nodes to the cluster as per requirements. In the module of MapReduce primitives of data processing are called reducers and mappers.
To decompose the application of data processing, sometimes nontrivial, the MapReduce framework contains scalability.
MapReduce is the programming model used in a HDDS, the main purpose of this framework is to access a large amount of data. By using MapReduce, we run multiple machines. Also, the MapReduce framework allows to write of scalable and distributed jobs by using little effort.
Conclusion
MapReduce is the programming model of distributed computing which was used in the framework of HDFS. Spark needs a lot of memory, while MapReduce does not require a lot of memory, it will store data on the disk. Spark is loading the process into the memory and keeping the same until further notice for the caching.
Recommended Articles
This is a guide to Spark vs MapReduce. Here we discuss the Spark vs MapReduce key differences with infographics and a comparison table in detail. You can also go through our other suggested articles to learn more –
Are you preparing for the entrance exam ?
Join our Data Science test series to get more practice in your preparation
View More