
Definition of HBase vs HDFS
HBase vs HDFS both are different terms, which are components of big data. HBase contains java based but it is not only the SQL database. Hdfs is a file system based on java and it is used to store large data sets. Hdfs contains a rigid architecture that does not allow changes and does not facilitate dynamic storage. Hbase allows dynamic changes. Hdfs and HBase both are important terms.
Table of contents
Difference between HBase vs HDFS
For write-once and read-many-times uses, HDFS is the best choice. For random write and read operations on data stored in HDFS, HBase is the best option. Hadoop distributed file system, which is an abstraction of the local file system, is good for storing large files but does not offer tabular storage as such.
HDFS is the foundation for a distributed column-oriented data store that runs on top of Hadoop and provides structural data models. Data is stored in a table row column. The easiest way to show that HBase is well suited for real-time environments. We jointly create and extract crucial insights from the logs of application/web servers. Given the rapid data flow, we choose HBase over HDFS because HDFS does not enable real-time writes.
What is HBase?
It will allow limitless read and write access on HDFS. A data consumer uses Hbase to read data from HDFS. HDFS supports the column-oriented HBase database. There are various horizontal scalability alternatives for this project. Hbase allows random access to structured data and makes use of a Hadoop error tolerance system.
Data exchange is automatic and flexible. Hbase offers failover on demand. Low-latency operations are the purpose for which Hbase was designed. HBase has a lot of reading and writing activities going on. There is a considerable amount of data in table form in Hbase. Hbase offers both linear and modular scalability.
The top-level Apache project HBase was created in Java to address the demand for real-time reading and writing of data. It offers a straightforward interface for dispersed data. It stores data in HDFS and may be accessed by MapReduce.
What is HDFS?
The Hadoop Distributed File System is a distributed file system created to store data reliably across several machines that are linked together as nodes. It consists of clusters, and each cluster’s method is monitored and managed by a single Name Node software program that is installed on a different workstation.
The best option for batch analytics is HDFS. But one of its main flaws is that it can’t conduct real-time analysis, which is a trend in the IT sector. On the other hand, HBase is better suited for batch analytics and can handle massive data volumes. It instantly publishes and reads data from Hadoop.
Head to Head Comparison Between HBase vs HDFS (Infographics)
Below are the top 9 differences between HBase and HDFS:
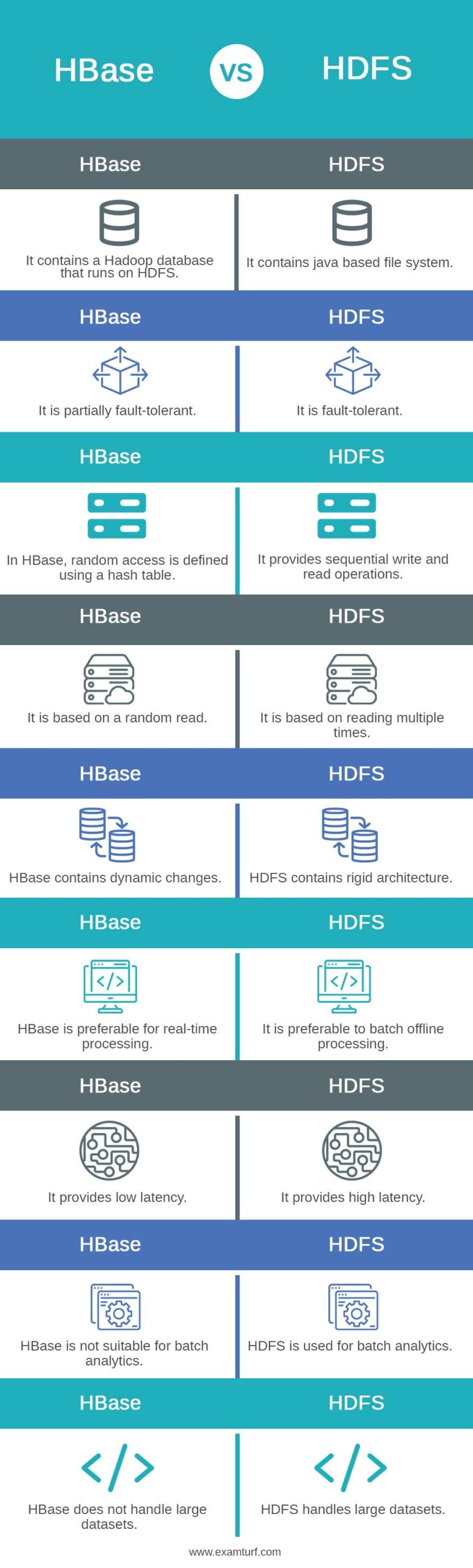
Key Differences between HBase vs HDFS
Let us look at the key differences between HBase and HDFS:
- Even during system failures, HDFS provides quick data movement across nodes since it is fault-tolerant by design. On top of Hadoop, HBase is a Not-Only-SQL database that is open source and non-relational. The CAP theorem applies to HBase in its CP type.
- Data that is structured, semi-structured, or unstructured can be processed using HDFS and HBase. As HDFS uses the outdated MapReduce algorithm, data analysis is slowed down by the lack of an in-memory processing engine. Contrarily, HBase boasts significant speeds up read/write operations.
- When performing data analysis, HDFS is quite open and transparent. HBase, a NoSQL tabular database, retrieves values by classifying them according to various key values. The easiest way to show that HBase is well suited for real-time environments is to use our client. We jointly created and extract crucial insights from the logs of applications or web servers.
- Large data sets can be accessed with low latency using HBase whereas HDFS offers high latency operations. WORM is supported by HDFS, but HBase allows random reads and write. MapReduce tasks are essentially or mostly used to access HDFS, whereas Avro or Thrift API is used to access HBase.
HBase Requirement
HBase uses caches to fill the memory; as a result, running HBase needs a lot of RAM. Installing Hbase requires the following hardware.
- To install Hbase, a distinct Hadoop user must be created.
- Java 1.7 or a later version is required to install HBase on our system.
- We must install and configure HDFS to use Hbase.
- Hbase can be set up on Windows and Linux systems.
- Installing Hbase requires at least 1 GB of storage space.
- The HBase log must be stored on a disc that has a minimum capacity of 500 MB.
HDFS Requirement
The fault-tolerant and scalable HDFS is a part of Hadoop. This document’s goals are to provide an overview of the requirements that Hadoop DFS should aim to meet and to provide additional development guidance. To use the HDFS we need the following requirements as follows.
- The maximum size of nodes in HDFS is 10 thousand.
- The total data size of HDFS is 10 10 PB.
- The number of files of HDFS is 100 Million.
- The number of clients is 100 thousand.
- Hdfs accepts data loss of 1 hour.
- It will accept a downtime level of 2 hours.
Comparison Table of HBase vs HDFS
The table below summarizes the comparisons between HBase vs HDFS:
| HBase | HDFS |
| It contains a Hadoop database that runs on HDFS. | It contains java based file system. |
| It is partially fault-tolerant. | It is fault-tolerant. |
| In HBase, random access is defined using a hash table. | It provides sequential write and read operations. |
| It is based on a random read. | It is based on reading multiple times. |
| HBase contains dynamic changes. | HDFS contains rigid architecture. |
| HBase is preferable for real-time processing. | It is preferable to batch offline processing. |
| It provides low latency. | It provides high latency. |
| HBase is not suitable for batch analytics. | HDFS is used for batch analytics. |
| HBase does not handle large datasets. | HDFS handles large datasets. |
Purpose of HBase
A NoSQL database called Apache Hbase makes use of HDFS. Real-time data processing can be done with Hbase. The database type that functions well for OLTP applications is Hbase. In Hbase, various columns have been created from several tables. In other words, HBase processes and stores hadoop data in response to read and write requests made by applications in real-time.
Both structured and unstructured data are present in HBase, and as is already known, it has low latency. To access the data, command shells are another option. Large brands will be housed in storage tiers on Hadoop clusters that are used by Hbase for storage.
Purpose of HDFS
A DFS named HDFS is included with Hadoop. To ensure data resilience and high availability for concurrent applications, HDFS distributes and replicates data across a number of computers. Due to the usage of inexpensive hardware, it is cost-effective. The concepts of blocks, data nodes, and node names are all present.
Applications using Hadoop mostly employ HDFS for data storage. A distributed file system called HDFS uses a node to achieve high-performance data access across massively scaled Hadoop clusters. To manage data processing and storage for large data application platforms. One of the many components of the Hadoop ecosystem is HDFS. It offers a dependable way to handle massive data pools.
Conclusion
The hadoop distributed file system, an abstraction of the local file system, is good for storing large files but does not offer tabular storage. Hdfs is a file system based on java and it is used to store large data sets. Hdfs contains a rigid architecture that not allowing changes, it was not facilitating dynamic storage.
Recommended Articles
This is a guide to HBase vs HDFS. Here we discuss HBase vs HDFS key differences with infographics and a comparison table in detail. You can also go through our other suggested articles to learn more –
Are you preparing for the entrance exam ?
Join our Data Science test series to get more practice in your preparation
View More