Definition of Hadoop vs Spark
Hadoop vs spark is defined as a storage framework that stores files and apache Hadoop started from the project of 2006 in yahoo. Apache spark is a general-purpose and open-source computing framework. Apache spark provides an interface for clusters using fault tolerance and implicit data parallelism. Apache Hadoop is a software utility that helps in problem-solving by utilizing a network of many computers.

Table of contents
Difference Between Hadoop vs Spark
Hadoop reads and writes files to the Hadoop-distributed file system, whereas spark process data into RAM using the RDD concept. We are running spark by using the standalone mode. Using the Hadoop cluster, we are serving the data source by using a conjunction of Mesos.
Basically, Spark is structured by using a spark core. The engine drives the optimization schedule and the abstraction of RDD and will connect to the correct file system. Multiple libraries operate on the top of core spark, including Spark SQL, which allows us to run SQL commands onto the distributed dataset.
What is Hadoop?
We can say that apache Hadoop is a software utility that allows users to manage big data sets by enabling the network components to solve vast data problems. Hadoop is a cost-effective and highly scalable solution that stores and processes structured, unstructured and semi-structured data. Hadoop is the most popular framework used for data processing.
Below are the benefits of using the Hadoop framework are as follows. It will contain multiple benefits.
- Protecting data at the time of hardware failure.
- It contains scalability; we can add multiple servers to the cluster.
- Open source
- Real-time data for decision-making and analysis of the processes.
- Data security will contain high data security.
- We can add multiple nodes to the server to secure the data.
What is Spark?
Apache spark is also open source engine of data processing for big data sets. Like Hadoop, it also splits large tasks into multiple nodes. It performs faster than Hadoop, and Spark uses random access memory for processing and caching the data into a file system. It enables the spark to handle multiple use cases.
Below are the benefits of the spark framework as follows. It contains multiple benefits while using it.
- Spark is a unified SQL engine that supports streaming data, SQL queries, graph processing, and machine learning.
- Spark is 100 times faster than the Hadoop framework for handling small tasks using in-memory processing.
- In spark, we are designing the API for manipulating the semi-structured data.
Head-to-Head Comparison Between Hadoop vs Spark (Infographics)
Below are the top 11 differences between Hadoop and Spark:
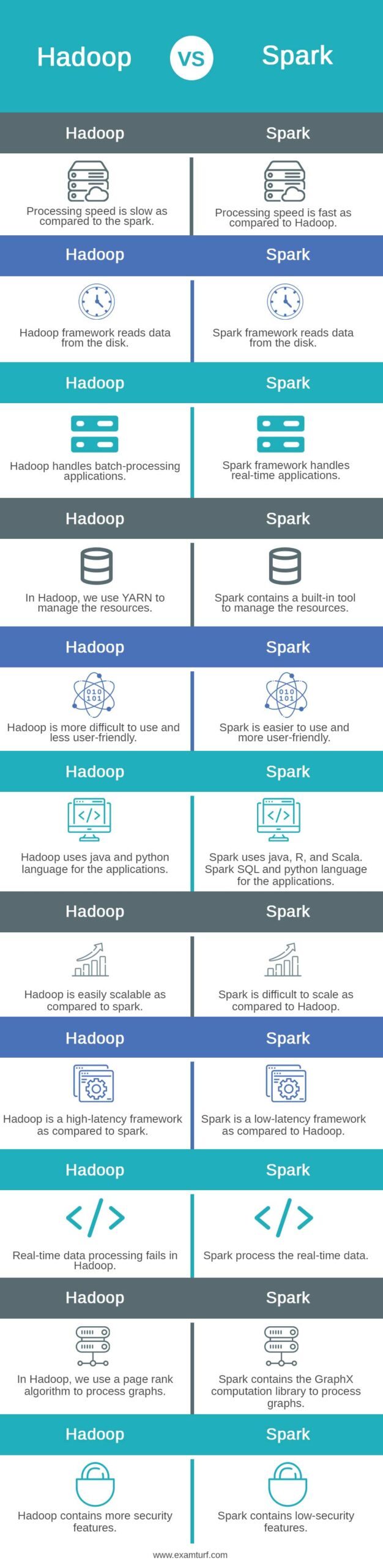
Key Differences between Hadoop and Spark
Let us look at the key differences between Hadoop and Spark:
- Apache Hadoop contains a slow performance compared to spark because it uses a disk for storage and to read and write operations. Spark contains a high performance as compared to Hadoop because it uses RAM.
- Hadoop is open source, so it is less expensive. It uses consumer hardware to store the data. Spark is also open source, but it will rely on memory, increasing the cost of running compared to Hadoop.
- Hadoop is good for the application of batch processing. It uses map-reduce algorithms to split a larger dataset into clusters. Spark framework is used for live streaming and iterative analysis of data.
- Hadoop contains a system as highly fault tolerant. It replicates the data across the nodes, and we use the same in case of any issue. Spark tracks the block creation of the RDD process, and then it will rebuild the dataset when our partition fails. Spark is used in the DAG.
- We can easily scale the Hadoop framework while adding the node and disk for the storage, it supports thousands of nodes. Spark is not easy to scale the nodes because it relies on memory.
- Hadoop is more secure as compared to the spark framework because it uses LDAP, Kerberos, and ACLs. Spark is not secure as compared to the Hadoop framework. By default, the security of spark is turned off. It relies on the integration of Hadoop to achieve security.
Hadoop Requirement
BDD supports the following distribution of Hadoop. Below requirements of Hadoop are as follows.
- Cloudera Hadoop distribution from 5.8.x to 5.11.x
- Data platform of hortonworks (2.4.2+)
- Data platform of MapR (5.1+)
To use Hadoop, we require the below components. We need to install the same on all nodes. It will run the required components if we install it on a single node.
- Cluster manager: The cluster manager depends on the distribution of Hadoop. The installer used the restful API for port numbers and nodes of Hadoop.
- Zookeeper: BDD has used the zookeeper to manage the instances of graphs to ensure availability.
- HDFS/MapR: This table contains the source data stored in the HDFS.
- YARN: It is a node manager service that runs all data processing jobs.
- Spark on yarn: BDD uses the spark on yarn for running the data processing jobs.
- Hive: All the data is stored in the tables of the hive.
- Hue: We can use the hue for loading the source data for viewing data exported from the studio.
Spark Requirement
While installing the spark, we need to check that our system meets the following prerequisites as follows.
- HDP cluster 3.0+
- Version of ambari 2.7+
- Yarn and HDFS are deployed onto the cluster.
After installing the above requirements, we need to check the following recommendation and requirements for spark services.
- The spark server requires Hive to be deployed in our cluster.
- Spark is required to install R binaries onto all nodes.
- We are accessing the spark by using Livy, so we require Livy to be installed on the cluster.
- Pyspark is required python 2.7+ installed on all nodes.
- For the performance of MLlib, we need to install netlib-java library.
Comparison Table of Hadoop vs Spark
The table below summarizes the comparisons between Hadoop vs Spark:
| Hadoop | Spark |
| The processing speed is slow as compared to the spark. | Processing speed is fast as compared to Hadoop. |
| The Hadoop framework reads data from the disk. | Spark framework reads data from the disk. |
| Hadoop handles batch-processing applications. | Spark framework handles real-time applications. |
| In Hadoop, we use YARN to manage the resources. | Spark contains a built-in tool to manage the resources. |
| Hadoop is more difficult to use and less user-friendly. | Spark is easier to use and more user-friendly. |
| Hadoop uses java and python language for the applications. | Spark uses java, R, and Scala. Spark SQL and python language for the applications. |
| Hadoop is easily scalable as compared to spark. | Spark is difficult to scale as compared to Hadoop. |
| Hadoop is a high-latency framework as compared to spark. | Spark is a low-latency framework as compared to Hadoop. |
| Real-time data processing fails in Hadoop. | Spark process the real-time data. |
| In Hadoop, we use a page rank algorithm to process graphs. | Spark contains the GraphX computation library to process graphs. |
| Hadoop contains more security features. | Spark contains low-security features. |
Purpose of Hadoop
The main purpose of Hadoop is to use an open-source framework that is used to store and process data datasets. In Hadoop, we use clustering to store data in multiple nodes. Hadoop is making processing and storage capacity easier for the cluster server, which we execute in distributed environments.
Hadoop provides the application building blocks on which we are running the service of Hadoop. An application collects the data in multiple formats. We are storing the same in Hadoop using API, which connects to the name node. The Hadoop name mode tracks the structure of the file directory and chunk placement which was replicated onto the data nodes.
Purpose of Spark
We use spark for our real-time application because it processes the data from memory using RDD. Spark framework is structured around using spark core, the engine which was driving the scheduling, RDD abstraction, and optimization as well will correcting the file systems.
Spark contains multiple libraries which operate on top of spark, which allows us to run the SQL commands onto the distributed data sets. Spark contains multiple APIs.
Conclusion
Spark contains a high performance as compared to Hadoop because it uses RAM. Hadoop reads and writes the files to Hadoop distributed file system, whereas spark process data into the RAM using the RDD concept. We are running spark by using a standalone mode.
Recommended Articles
This is a guide to Hadoop vs Spark. Here we discuss Hadoop vs Spark key differences with infographics and a detailed comparison table. You can also go through our other suggested articles to learn more –
Are you preparing for the entrance exam ?
Join our Data Science test series to get more practice in your preparation
View More