
Difference Between Apache Storm vs Spark
Apache Storm vs Spark will provide a complete overview of the difference between Storm and Spark which operate in a Hadoop cluster and to access Hadoop Storage. Apache storm is a Stream processing engine that processes real-time streaming data whereas Apache Spark is a computing engine, referred to as distributed processing. Apache Spark and Apache Storm are designed in a way they can operate in the Hadoop cluster and access the Hadoop cluster. In this article, we shall see the differences between Apache Spark vs Storm, the requirements for Apache Storm and Spark, and their purpose.
What is Apache Storm?
Apache Storm is distributed and real-world data processing system and is designed in such a way that it processes fault-tolerant and horizontal scalable data. Apache Storm is a streaming data framework which processes the highest ingestion rates.
Even though it is stateless, Storm can handle cluster state and distributed environment via Apache Zookeeper. The professionals in the IT sector consider Storm to as Hadoop for real-time processing. It is developed with abilities required for rapid conventional processes.
Apache Storm offers REST API which enables users to communicate with Storm cluster that involves fetching metric data and handling operations of starting and stopping topologies with a process of 1 million messages of 100 bytes in a single node, operating on “fail-fast-auto restart. Each node is processed “exactly once or at least once”, even in case of failure.
What is Apache Spark?
Apache Spark is a freeware distributed processing system that users use for big data workloads, that uses optimal query execution, and memory caching that helps for rapid analytic queries against any type of data. It offers development APIs in Java, Python, R, and Scala and helps in code reuse with multiple workloads throughout, like batch processing, interactive queries, graph processing, batch processing, real-time analytics, and machine learning.
Apache Spark provides less read-to and writes from multi-threaded disk tasks in JVM processes. It offers querying and high-speed data analytics and transformation with data sets, is suitable for iterative algorithms, and is rapid for interactive queries.
Head-to-Head Comparison Between Apache Storm vs Spark (Infographics)
Below are the top 12 differences between Apache Storm and Spark:
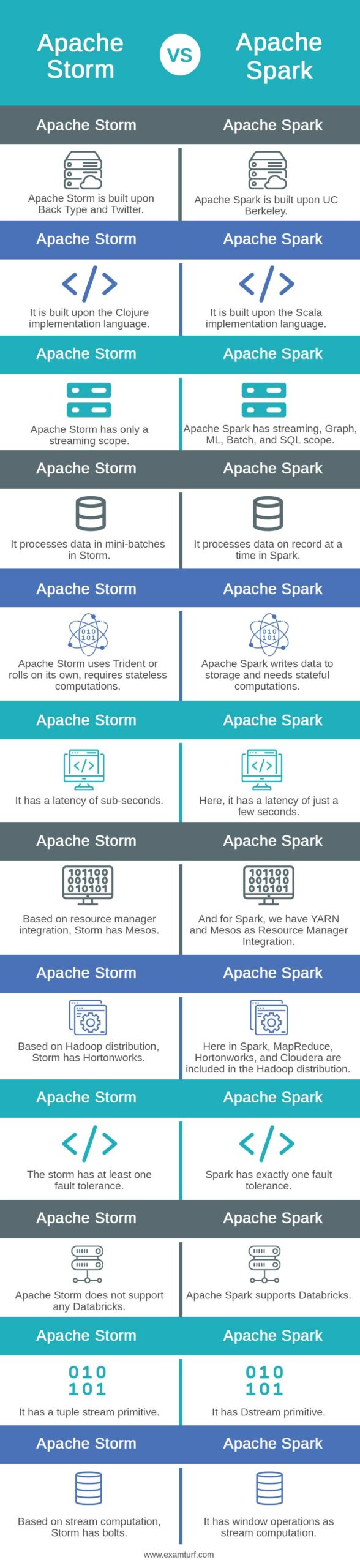
Key Difference between Apache Storm vs Spark
Below are the key differences between Apache Storm vs Spark,
- Apache Storm offers a massive set of primitives to perform tuple-level processes, including left, right,, and inner join through the stream.
- Apache Spark offers various operators like “Stream-Transformation-Operators”, which convert DStream to another DStream, and “Output Operator”, which writes data to an external system.
- Apache Strom by default will not provide any framework-level support, for saving intermediate-level bolt as a state, and hence, an application must update or create a state when required.
- Output is processed by Apache Spark for each RDD operation as an intermediate state, and saved as RDD.
- In Apache Spark, the driver node is SPOF. If the driver node fails, all executors are gone with the replicated and received in-memory information whereas Apache Storm daemons and built to be stateless and are mapped for fault tolerance.
- Apache Spark runs on a different application which runs on the YARN cluster when each executor deploys in the other YARN container.
- Apache Storm helps in integrating various topology tasks that do not allow worker process which supports topology-level runtime.
Apache Storm Requirement
Below mentioned are the requirements for Apache Storm,
- Apache Storm requires good memory with adequate processing power, and machine configurations for development systems and production systems are different.
- For development systems, 1 CPU and 1 TB hard disk is required, along with a minimum of 2 GB RAM.
- For production systems, at least 6 Core CPUs are recommended and up to 32 GB of RAM per machine is required.
- 1 GB of Ethernet and processors with 2GHz or higher with a minimum of 16 GB RAM are a few of the requirements for Apache Storm
Apache Spark Requirement
Below mentioned are the requirements for Apache Spark,
- Minimum hardware requisites for evaluation for Compute hosts and Management hosts are different.
- CPU power for Compute and Management hosts should be >=2.4GHz and RAM size are 8GB and 16GB for Compute and Management hosts respectively.
- 12 GB of disk space is needed to install Apache Spark and additional disk space can be 30 GB for a large clusters.
Comparison Table of Apache Storm vs Spark
The table below summarizes the comparisons between Apache Storm vs Spark:
| Apache Storm | Apache Spark |
| Apache Storm is built upon BackType and Twitter. | Apache Spark is built upon UC Berkeley. |
| It is built upon the Clojure implementation language. | It is built upon the Scala implementation language. |
| Apache Storm has only a streaming scope. | Apache Spark has streaming, Graph, ML, Batch, and SQL scope. |
| It processes data in mini-batches in Storm. | It processes data on record at a time in Spark. |
| Apache Storm uses Trident or rolls on its own, requires stateless computations. | Apache Spark writes data to storage and needs stateful computations. |
| It has a latency of sub-seconds. | Here, it has a latency of just a few seconds. |
| Based on resource manager integration, Storm has Mesos. | And for Spark, we have YARN and Mesos as Resource Manager Integration. |
| Based on Hadoop distribution, Storm has Hortonworks. | Here in Spark, MapReduce, Hortonworks, and Cloudera are included in the Hadoop distribution. |
| The storm has at least one fault tolerance. | Spark has exactly one fault tolerance. |
| Apache Storm does not support any Databricks. | Apache Spark supports Databricks. |
| It has a tuple stream primitive. | It has Dstream primitive. |
| Based on stream computation, Storm has bolts. | It has window operations as stream computation. |
Purpose of Apache Storm
Apache Storm is famous for real-time big data stream processing and hence, most of companies use Storm as an integral part of the system. It provides reliability to process unbounded data streams for real-time processing similar to what Hadoop does for batch processing.
Apache Storm data model involves tuples and streams, consisting of bolts and spouts. Spouts create tuples that are processed by bolts. Though it is stateless, Storm manages the distributed environment and the cluster state through Apache Zookeeper.
Purpose of Apache Spark
Apache Spark is lightning-fast cluster computing technology designed for faster computation. The main feature of Apache Spark is it’s in-memory cluster computing which increases the processing speed of applications.
Many benefits of Apache Spark include multiple workloads, fast in memory caching, and is developer friendly. Apache Spark DAG has multiple stages which can be distributed in an efficient manner.
Conclusion
Hereby we can come to conclusion on the topic “Apache Storm vs Spark”. We have seen what is “Apache Storm vs Spark” and the difference between Apache Storm and Apache Spark. Have gone through individually on Apache Storm and Spark and listed out key differences, individual requirements, and their purposes. Thanks! Happy Learning!!
Recommended Articles
This is a guide to Apache Storm vs Spark. Here we discuss Apache Storm vs Spark key differences with infographics and a comparison table in detail. You can also go through our other suggested articles to learn more –
- Data Science vs Data Mining
- Data Scientist vs Data Analyst
- Data Science vs Data Engineering
- Big Data vs Machine Learning
Are you preparing for the entrance exam ?
Join our Data Science test series to get more practice in your preparation
View More